
Refactoring Towards Resilience: A Primer

Other posts in this series:
- A primer
- Evaluating Stripe Options
- Evaluating SendGrid Options
- Evaluating RabbitMQ Options
- Evaluating Coupling
- Async Workflow Options
- Process Manager Solution
Recently, I sat down to help a team to put in some resiliency in a payment page. This payment page used Stripe as its payment gateway. Along with accepting payment, this action had to perform a number of other actions. Roughly, the controller action looked something like:
public async Task<ActionResult> ProcessPayment(CartModel model) {
var customer = await dbContext.Customers.FindAsync(model.CustomerId);
var order = await CreateOrder(customer, model);
var payment = await stripeService.PostPaymentAsync(order);
await sendGridService.SendPaymentSuccessEmailAsync(order);
await bus.Publish(new OrderCreatedEvent { Id = order.Id });
return RedirectToAction("Success");
}
I'm greatly simplifying things, but these were the basic steps of the order:
- Find customer from DB
- Create order based on customer details and cart info
- Post payment to Stripe
- Send "payment successful" email to customer via SendGrid
- Publish a message to RabbitMQ to notify downstream systems of the created order
- Redirect user to a "thank you" page
Missing in this flow are the database transaction commits, that's taken care of in a global filter:
config.Filters.Add(new DbContextTransactionFilter());
I see this kind of code quite a lot with people working with HTTP-based APIs, where we make a lot of assumptions on the success and failure of requests. Ever since we've had RPC-centric APIs to interact with external systems, you'll see a myriad of assumptions being made.
In our RESTful centric world we live in now, it's easy to patch together and consume APIs, but it's much more difficult to reason about the success and failure of such systems. So what's wrong with the above code? What could go wrong?
Remote failures and missing money
Looking closely at our request flow, we have some items inside a DB transaction, and some items not:
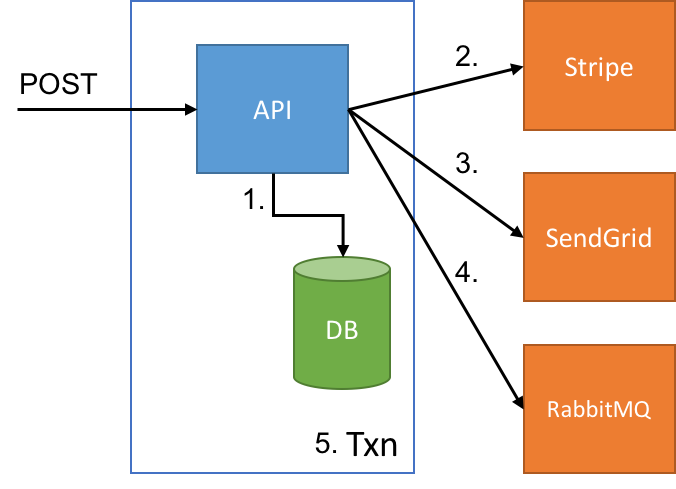
After the first call to the database (inside a transaction) to build up an order, we start to make calls to other APIs that are not participating in our transaction. First, to Stripe to charge the customer, then to SendGrid to notify the customer, and finally to RabbitMQ. Since these other services aren't participating in our transaction, we need to worry about what happens if those other systems fail (as well as our own). One by one, what happens if any of these calls fail?
- DB call fails - transaction rolls back and system is consistent
- Stripe call fails - no money is posted and transaction rolls back
- SendGrid call fails - customer is charged but transaction rolls back
- RabbitMQ call fails - customer is charged and notified but transaction rolls back
- DB commit fails - customer is charged and notified and downstream systems notified but transaction rolls back
Clearly any failures after step 2 are a problem, since we've got downstream actions that have happened, but no record of these things happening in our system (besides maybe a log entry).
To address this, we have many options, and each will depend on the resiliency options of each different service.
Resiliency and Coffee Shops
In Gregor Hohpe's great paper, Your Coffee Shop Doesn't Use Two-Phase Commit, we're presented with four options with handling errors in loosely-coupled distributed systems:
- Ignore
- Retry
- Undo
- Coordinate
Each of these four options coordinates one (or more) distributed activities:
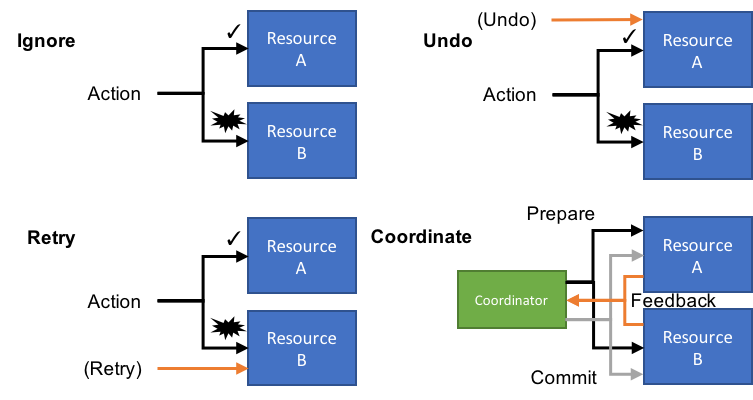
Which we decide for each interaction will highly depend on what's available for each individual resource. And of course, we have to consider the user and what their expectation is at the end of the transaction.
In this series, I'll walk through options on each of these services and how messaging patterns can address failures in each scenario, with (hopefully) our brave customer still happy by the end!