
Life Beyond Distributed Transactions: An Apostate's Implementation - Relational Resources

Posts in this series:
- A Primer
- Document Coordination
- Document Example
- Dispatching Example
- Failures and Retries
- Failure Recovery
- Sagas
- Relational Resources
- Conclusion
So far in this series we've mainly concerned ourselves with a single resource that can't support distributed (or multi-entity) transactions. While that is becoming less common as NoSQL options, as Azure CosmosDB supports them, and with the 4.0 release, MongoDB now supports multi-document transactions.
What does this mean for us then?
Firstly, there are many cases that even though transactions between disparate entities is possible, it may not be desired. We may have to make design or performance compromises to make it work, as the technology to perform multi-entity transactions will always add some overhead. Even in SQL-land, we still often need to worry about consistency, locks, concurrency, etc.
The scenario that is most often overlooked I've found is bridging disparate resources, not multiple entities in the same resource (such as with many NoSQL databases). I've blogged about resilience patterns, especially crossing incorporating calling APIs to external sources. Most typically though, I see people trying to write to a database and send a message to a queue:
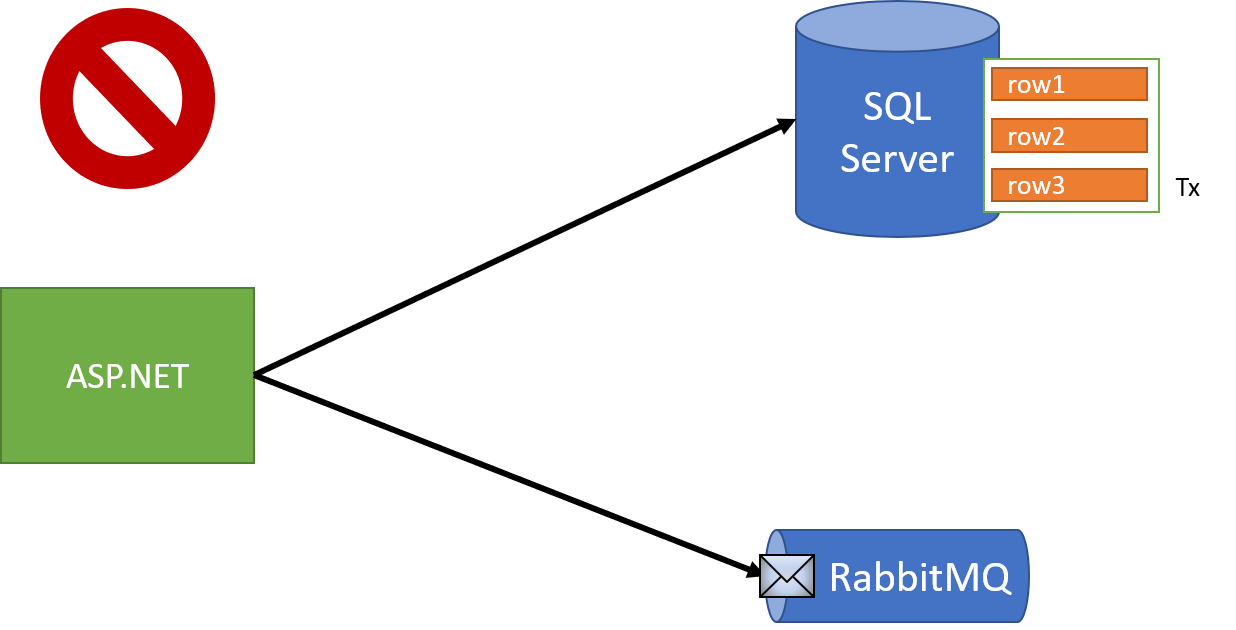
The code is rather innocuous - we're trying to do some stuff in a database, which IS transactional across multiple writes, but at the same time, try to write to a queue/broker/exchange like RabbitMQ/Azure Service Bus.
While it may be easy/obvious to spot places where we're trying to incorporate external services into our business transactions, like APIs, it's not so obvious when it's infrastructure we do own and is transactional.
Ultimately, our solution will be the same, which is to apply the outbox pattern.
Outbox pattern generalized
With the Cosmos DB approach, we placed the outbox inside each individual document. This is because our transactional boundary is a single item in a single collection. In order to provide atomicity for "publishing" messages, we need to design our outbox to the same transactional scope as our business data. If the transactional scope is a single record, the outbox goes in that record. If the scope is the database, the outbox goes in the database.
With a SQL database, our transaction scope widens considerably - to the entire database! This also widens the possibilities of how we can model our "outbox". We don't have to store an outbox per record in SQL Server - we can instead create a single outbox for the entire database.
What should be in this outbox table? Something similar to our original outbox in the Cosmos DB example:
- Message ID (which message is this)
- Type (what kind of message is this)
- Body (what's in the message)
We also need to keep track of what's been dispatched or not. In the CosmosDB example, we keep sent/received messages inside each record.
With SQL though, having a single table that grows without bound is...problematic, so we need some more information about whether or not a message has been dispatched, as well as a dispatch date to be able to clean up after ourselves.
We can combine both into a single value however - "DispatchedAt", as a timestamp:
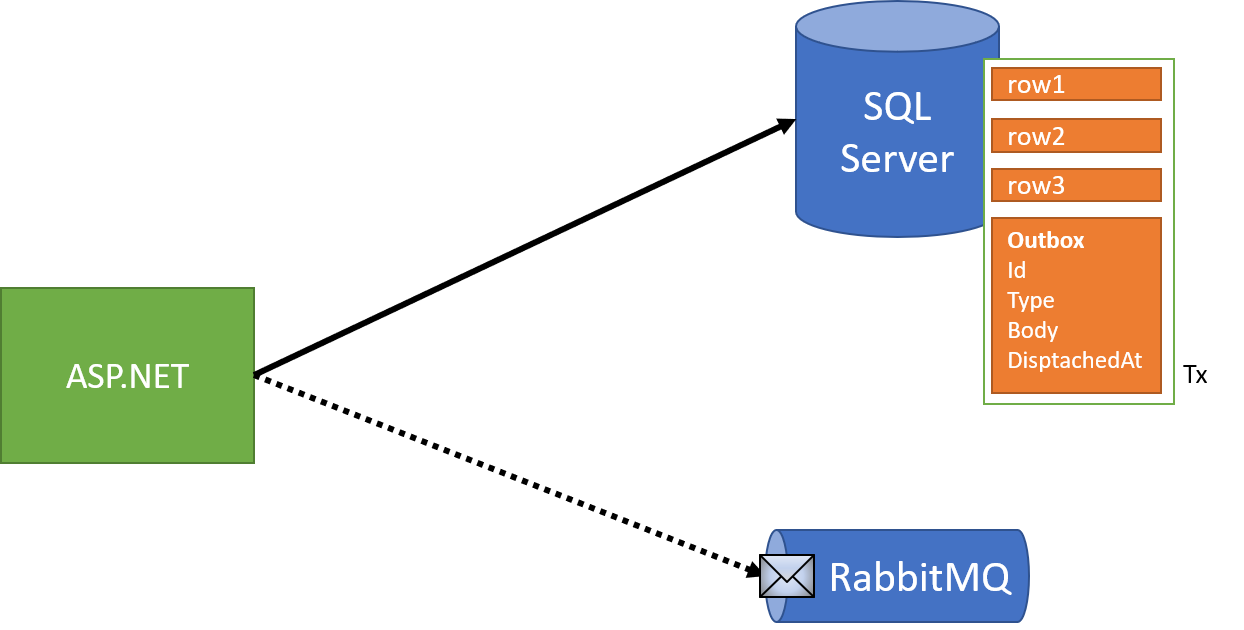
Processing the outbox will be a bit different than our original Cosmos DB example, since we now have a single table to deal with.
Sending via our SQL outbox
In the Cosmos DB example, we used domain events to communicate. We can do similar in our SQL example, but we'll more or less need to draw some boundaries. Are our domain events just to coordinate activities in our domain model, or are they there to interact with the outside world as service-level integration events? Previously, we only used them for domain events, and used special domain event handlers to "republish" as service events.
There are lots of tradeoffs between each approach, but in general, it's best not to combine the idea of domain events and service events.
To keep things flexible, we can simply model our messages as plainly as possible, to the point of just including them on the DbContext:
public Task SaveMessageAsync<T>(T message)
{
var outboxMessage = new OutboxMessage
{
Id = Guid.NewGuid(),
Type = typeof(T).FullName,
Body = JsonConvert.SerializeObject(message)
};
return Outbox.AddAsync(outboxMessage);
}
When we're doing something that needs any kind of messaging, instead of sending directly to a broker, we save a new message as part of a transaction:
using (var context = new AdventureWorks2016Context())
{
using (var transaction = context.Database.BeginTransaction())
{
var product = await context.Products.FindAsync(productId);
product.Price = newPrice;
await context.SaveMessageAsync(new ProductPriceChanged
{
Id = productId,
Price = newPrice
});
await context.SaveChangesAsync();
transaction.Commit();
}
}
Each request that needs to send a message does so by only writing to the business data and outbox in a single transaction:
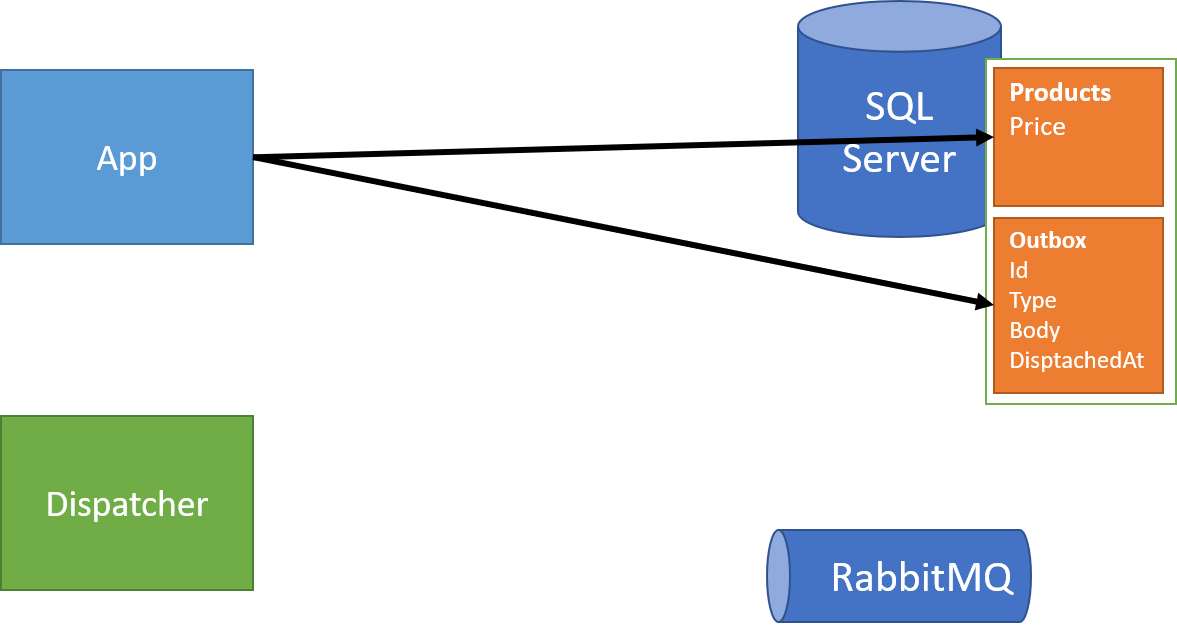
Then, as with our Cosmos DB example, a dispatcher reads from the outbox and sends these messages along to our broker:
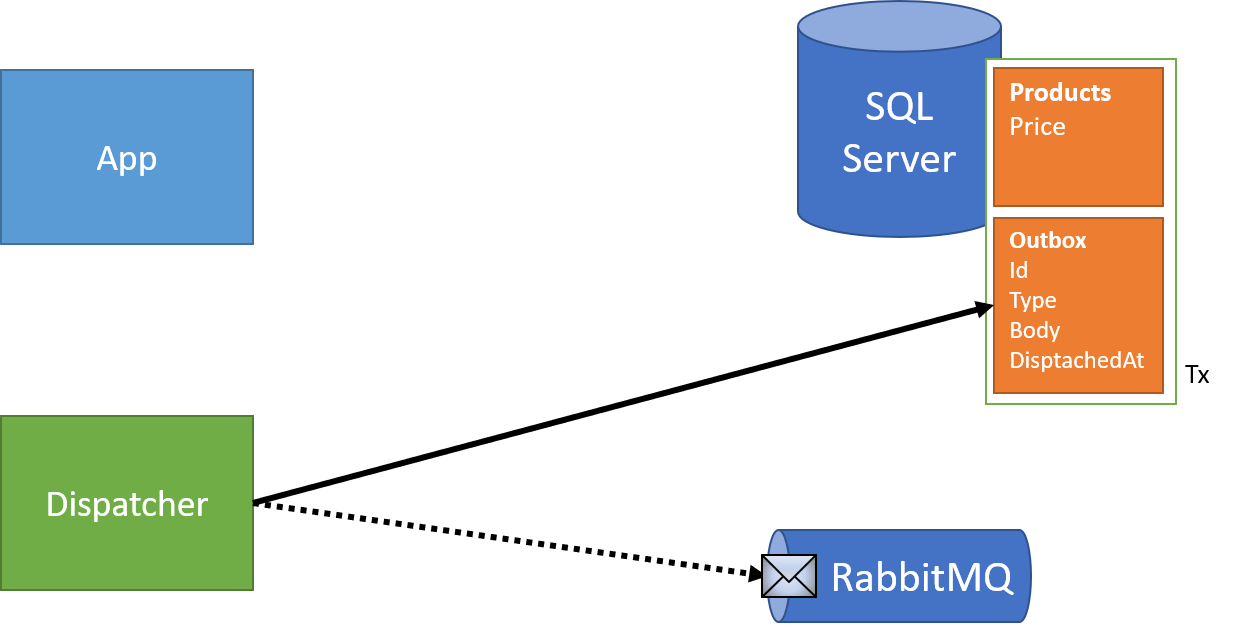
And also like our Cosmos DB example, our dispatcher can run right after the transaction completes, as well as a background process to "clean up" after any missed messages. After each dispatch, we'd set the date of dispatch to ensure we skip already dispatched messages:
using (var context = new AdventureWorks2016Context())
{
using (var transaction = context.Database.BeginTransaction())
{
var message = await context.Outbox
.Where(m => m.DispatchedAt == null)
.FirstOrDefaultAsync();
bus.Send(message);
message.DispatchedAt = DateTime.Now;
await context.SaveChangesAsync();
transaction.Commit();
}
}
With this in place, we can safely "send" messages in a transaction. However, we still have to deal with receiving these messages twice!
De-duplicating messages
In order to make sure we achieve at-least-once delivery, but exactly-once processing, we'll have to keep track of messages we've processed. To do so, we can just add a little extra information to our outbox - not just when we've sent messages, but when we've processed messages:
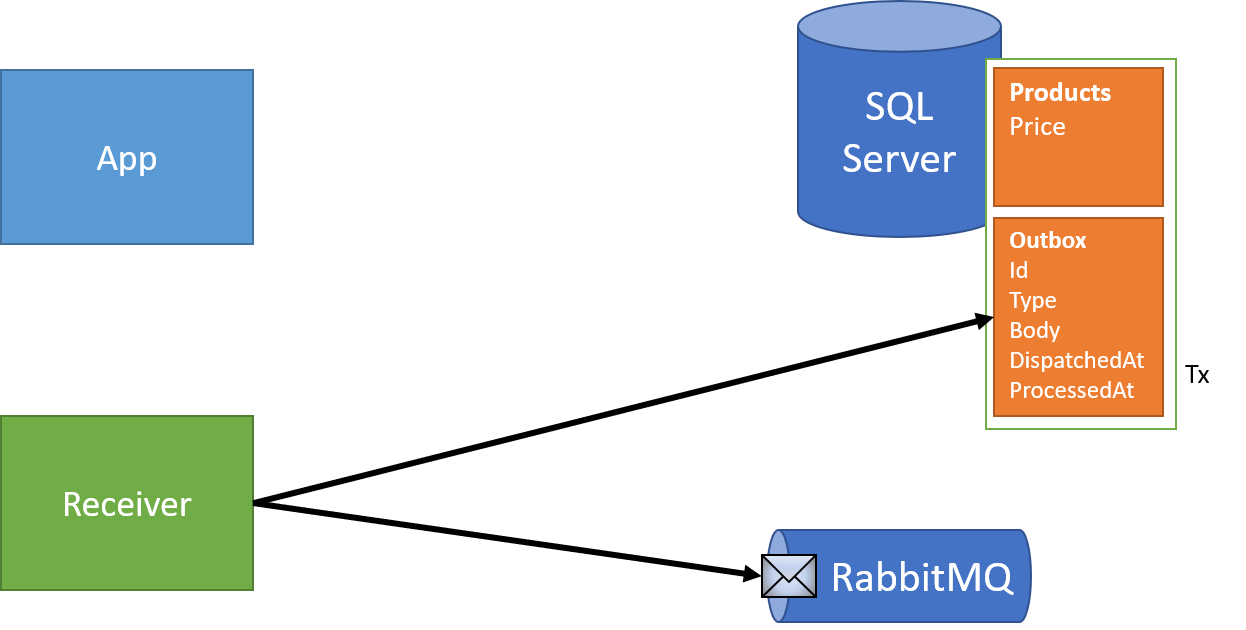
Similar to our inbox, we'll include the processed date with each message. As we process a message, we'll double-check our outbox to see if it's already processed before. If not, we can perform the work. If so, we just skip the message - nothing to be done!
With these measures in place, the last piece is to decide how long we should keep track of messages in our outbox. What's the longest amount of time a message can be marked as processed that we might receive the message again? An hour? A day? A week? Probably not a year, but something that makes sense. I'd start large, say a week, and move it lower as we understand the characteristics of our system.
With the outbox pattern, we can still coordinate activities between transactional resources by keeping track of what we need to communicate, when we've communicated, and when we've processed. It's like a little to-do list that our system uses to check things off as it goes, never losing track of what it needs to do.
In our last post, I'll wrap up and cover some scenarios where we should avoid such a level of coordination.